
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- yolo
- 파이썬 #업무자동화 #python
- pypdf2
- YOLOv7
- Google API
- Text To Speech
- ironpython
- DeepLearning
- YOLOv5
- pdf merge
- computervision
- 사무자동화
- Text-to-Speech
- 업무자동화
- objectdetection
- google cloud
- processstart
- 사무자동화 #Selenium
- pythonnet
- pyautogui
- Today
- Total
Doarchive
오토인코더(Auto Encoder) 본문
비지도학습(Unsupervised Learning) 의 한 종류로
데이터의 차원 축소(Dimensionality Reduction) ,잡음 제거(Denoising) 등에 사용되는 인공신경망 모델입니다
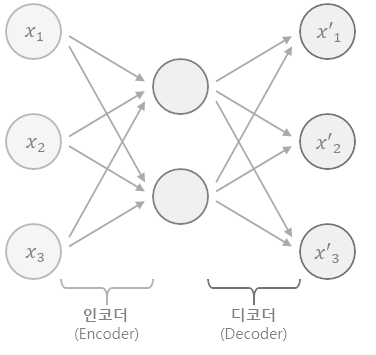
입력 데이터를 압축하는 인코더(Encoder)와 압축된 데이터를 복원하는 디코더(Decoder)로 구성되어 있는데
인코더는 입력 데이터를 저차원의 잠재 표현(Latent Representation)으로 변환하고, 디코더는 잠재 표현을 다시 원래의 차원으로 복원합니다.
인코더와 디코더는 각각 다른 인공신경망으로 구성되며, 이 네트워크는 학습을 통해 입력 데이터의 특징을 추출하고 압축하는 방법을 스스로 학습합니다.
이미지나 영상 데이터 처리에서 많이 활용되고 생성 모델(Generative Model)로도 사용될 수 있습니다
인코더에서 추출된 잠재 표현을 조작하여 새로운 데이터를 생성할 수도 있습니다.
하지만 오토인코더는 학습 데이터와 유사한 데이터만을 잘 처리할 수 있으며,
학습 데이터와 다른 패턴이나 노이즈가 포함된 데이터에 대해서는 성능이 떨어질 수 있습니다.
또 네트워크 구조나 하이퍼파라미터 설정 등에 따라 결과가 크게 달라질 수 있으므로 적절한 모델 설계와 학습 방법이 필요합니다.
Autoencoder(AE)는 입력 데이터를 압축(인코딩)하고, 다시 복원(디코딩)하는 과정을 통해 학습됩니다.
AE 모델의 목표는 입력 데이터와 디코딩된 데이터가 최대한 일치하도록 하는 것이며 , 재구성 손실(reconstruction loss)을 최소화하는 방향으로 학습됩니다.
재구성 손실(reconstruction loss) : 입력 데이터와 디코딩된 데이터의 차이를 나타내는 지표
VAE(Variational Autoencoder)는 Autoencoder(AE)의 확장된 모델로
VAE는 입력 데이터를 잠재 공간(latent space)의 확률 분포로 표현하고, 이를 통해 새로운 데이터를 생성할 수 있습니다.
VAE는 확률적인 잠재 공간을 모델링하고, 입력 데이터와 잠재 공간 간의 KL divergence를 최소화하는 방향으로 학습됩니다.
VAE의 잠재 공간은 AE와 달리 일정한 분포를 가지는 것이 아니라, 정규분포와 같은 분포를 따릅니다. 따라서 VAE를 이용해 잠재 공간에서 샘플링한 벡터는, 그 분포를 따르는 확률적인 값으로 해석할 수 있습니다.
VAE 장점
잠재 공간에서 샘플링을 통해 새로운 데이터를 생성할 수 있습니다.
잠재 공간의 확률 분포를 모델링함으로써, 입력 데이터의 노이즈나 변형에 대한 내성(robustness)을 강화할 수 있습니다.
확률 분포를 모델링함으로써, 다양한 데이터셋에 대한 생성 모델링이 가능합니다
VAE 단점
VAE는 분포 모델링을 위해 KL divergence를 사용하는데, KL divergence는 학습이 불안정하게 되는 문제가 있습
GAN(Generative Adversarial Network)의 Loss
Generator Loss:
생성된 데이터와 실제 데이터 간의 차이를 최소화하는 것이 목적
.일반적으로는 Binary Cross-Entropy Loss를 사용합니다. Generator가 생성한 이미지를 진짜로 분류하는 확률을 계산하고, 이 확률이 높아질수록 Generator Loss는 낮아집니다.
Discriminator Loss:
Discriminator Loss는 생성된 데이터와 실제 데이터 간의 차이를 최대화하는 것이 목적입니다. 이를 위해 일반적으로 Binary Cross-Entropy Loss를 사용합니다. Discriminator가 생성된 이미지를 진짜로 분류하는 확률과 실제 이미지를 진짜로 분류하는 확률을 계산하고, 이를 이용해 Discriminator Loss를 계산합니다.
GAN의 전체 Loss
Generator Loss와 Discriminator Loss를 더한 값. Generator와 Discriminator는 서로 대립적인 목적을 가지기 때문에, 학습이 안정적으로 이루어지기 위해서는 두 Loss의 균형을 유지하는 것이 중요하다
'Computer Vision > Deep learning' 카테고리의 다른 글
| 임베딩 차원을 늘렸을 때의 장단점 (0) | 2023.04.19 |
|---|---|
| Faster R-CNN (0) | 2023.04.18 |
| DC-GAN(Deep Convolutional Generative Adversarial Network) (0) | 2023.04.14 |
| GAN 모델의 종류 DCGAN , LSGAN , Conditional GAN (0) | 2023.04.13 |
| YOLOv7 사용 방법 (0) | 2023.04.05 |