
Notice
Recent Posts
Recent Comments
Link
250x250
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- computervision
- google cloud
- objectdetection
- pyautogui
- Google API
- 사무자동화
- DeepLearning
- ironpython
- 파이썬 #업무자동화 #python
- 사무자동화 #Selenium
- pythonnet
- yolo
- 업무자동화
- pypdf2
- pdf merge
- processstart
- Text To Speech
- Text-to-Speech
- YOLOv7
- YOLOv5
Archives
- Today
- Total
Doarchive
[Python 업무 자동화 ] 웹에 있는 모든 게시글 데이터 수집, 스크린샷 찍기 본문
728x90
Python의 Selenium 라이브러리와 PyAutoGUI 라이브러리를 활용하여 특정 사이트의 모든 포스트의 스크린샷을 자동으로 찍는 프로그램
프로그램 동작순서
1.URL에 접속해 해당 주소의 카테고리 내 모든 포스트들의 URL을 가져온다
2.각 포스트에 접속해 , 스크롤을 내리며 페이지 전체를 캡쳐후 저장한다
3.다음 포스트로 이동하여 2번 과정을 반복한다
간단한 특징
Selenium의 WebDriverWait 클래스를 사용하여 특정 요소가 나타날 때까지 기다린다
페이지의 스크롤을 내릴 때는 execute_script() 메서드를 사용하여 자바스크립트를 실행시키는 방식으로 스크롤을 내린다 PyAutoGUI의 screenshot() 메서드를 사용하여 이미지를 캡쳐한다
사용한 css selecter xpath는 본인이 사용한 페이지 특성에 맞게 바꿔줄것
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import pyautogui
chrome_options = Options()
#chrome_options.add_argument("--headless")
chrome_options.add_argument("start-maximized")
url = 'https://www.doaarchive.com'
capture_width = 950
capture_height = 1170
scroll_amount = 760
# Webdriver 객체 생성 및 옵션 설정
driver = webdriver.Chrome(options=chrome_options)
# 해당 URL로 이동
driver.get(url)
# 페이지가 로딩될 때까지 대기
wait = WebDriverWait(driver, 10)
# CSS 선택자를 사용하여 요소를 찾고, 요소 리스트 반환
elements = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '#content > div.wrap_search.box > div > ul:nth-child(2) > li')))
# 해당주소의 카테고리 내 타이틀 정보
# 리스트 컴프리헨션을 사용하여 리스트 생성
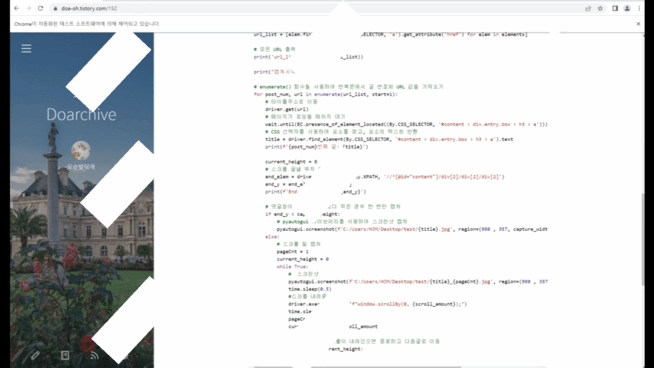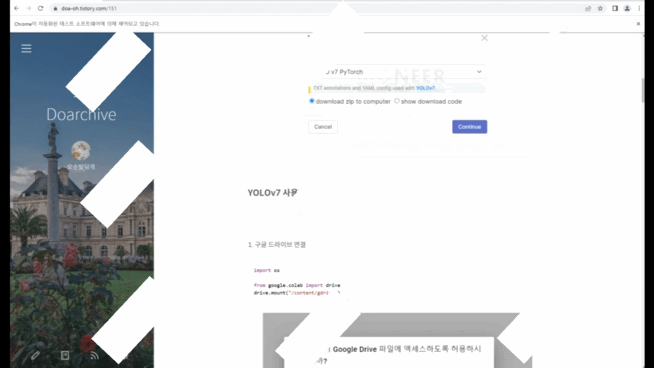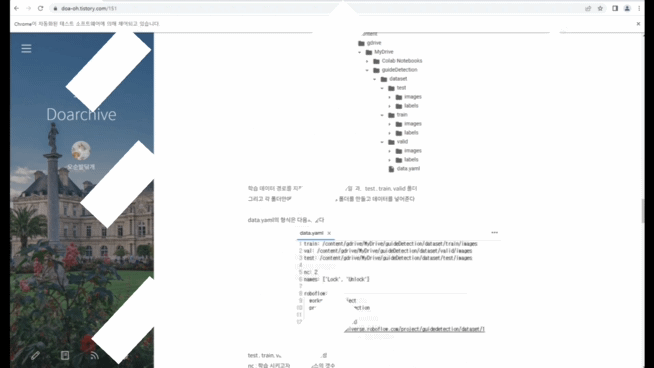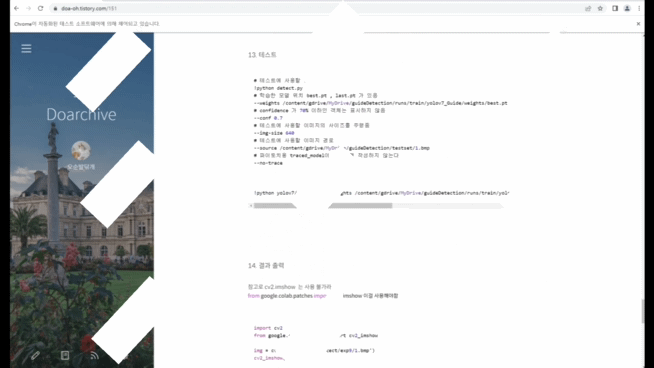
url_list = [elem.find_element(By.CSS_SELECTOR, 'a').get_attribute('href') for elem in elements]
# 모든 URL 출력
print('url_list: {}'.format(url_list))
print("캡쳐시작")
# enumerate() 함수를 사용하여 반복문에서 글 번호와 URL 값을 가져오기
for post_num, url in enumerate(url_list, start=1):
# 타이틀주소로 이동
driver.get(url)
# 페이지가 로딩될 때까지 대기
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#content > div.entry.box > h3 > a')))
# CSS 선택자를 사용하여 요소를 찾고, 요소의 텍스트 반환
title = driver.find_element(By.CSS_SELECTOR, '#content > div.entry.box > h3 > a').text
print(f'{post_num}번째 글: {title}')
current_height = 0
# 스크롤 끝낼 위치 댓글창 이전까지
end_elem = driver.find_element(By.XPATH, '//*[@id="content"]/div[2]/div[2]/div[2]')
end_y = end_elem.location['y']
print(f'End Y-coordinate: {end_y}')
# 댓글창이 캡처할 높이보다 작은 경우 한 번만 캡처
if end_y < capture_height:
# pyautogui 라이브러리를 사용하여 스크린샷 캡처
pyautogui.screenshot(f'C:/Users/HJM/Desktop/test/{title}.jpg', region=(998 , 357, capture_width , capture_height))
else:
# 스크롤 및 캡처
pageCnt = 1
current_height = 0
while True:
# 스크린샷
pyautogui.screenshot(f'C:/Users/HJM/Desktop/test/{title}_{pageCnt}.jpg', region=(998 , 357, capture_width , capture_height))
time.sleep(0.5)
#스크롤 내려줌
driver.execute_script(f"window.scrollBy(0, {scroll_amount});")
time.sleep(0.5)
pageCnt += 1
current_height += scroll_amount
#원하는 만큼 스크롤이 내려갔으면 종료하고 다음글로 이동
if end_y < current_height:
break728x90
'ETC > Python' 카테고리의 다른 글
| [Python] PyPDF2 로 PDF 문서 병합하기 (0) | 2023.06.20 |
|---|---|
| MQTT 사용 하기 Python , mosquitto (1) | 2023.06.14 |
| Python - divmod (0) | 2023.04.17 |
'ETC/Python' Related Articles
more
